原文地址:http://www.jayconrod.com/posts/44/polymorphic-inline-caches-explained
我(原作者)打算换到一个新的Team,从事优化 Android 上面 V8 引擎的工作。开始之前我做了一些准备工作,阅读了大量关于 JIT 编译优化方面的资料,因为之前我对编译器的经验主要来自于所从事的静态类型的编译语言。看了那些资料之后,我发现 JIT 编译器一个很有趣的地方就是可以在需要的时候即时生成机器码,而且后续还可以动态的调整和优化所生成的机器码。
Urs Hölzle 曾经用一个很有意思的例子介绍过 JIT 编译中的 Polymorphic Inline Cache(后续称作PIC) 技术。PICs 主要是用来优化动态语言中对函数多态调用的一种技术,从而可以保证在不同状态下函数的运行效率都尽可能的高。以 JavaScript 代码举例:
function add( a, b ) {
return a + b;
}
当我们调用 add 方法的时候,执行的逻辑跟 a 和 b 的类型是有关系的。在不同的参数类型下,JIT 编译器需要借助 PIC 技术来生成优化过的机器码,从而保证 add 这个函数的执行效率。再举个例子:
function feed(animal, food) {
animal.munch(food);
}
如果在静态类型语言中,在代码编译的阶段我们就能知道 animal 的类型及其 munch 的位置,调用的时候可以直接从 vtable 中找到(效率很高),然后执行即可。然而在动态类型语言中,从源代码我们无法获取到 animal 的任何类型信息(只能说它可能有munch这个方法),当我们调用 feed 方法的时候,无法直接调用 animal 的 munch 方法,必须先找到这个方法,然后才能调用。但是任何对象都可以拥有 munch 这个方法,因此我们无法提前知晓 munch 的位置信息,所以必要的时候我们可能会以哈希查找的方式来定位 munch 这个方法。
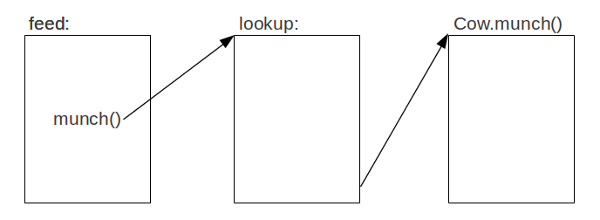
大部分情况下,调用函数的位置参数都是同样的类型,我们把这种情况称作单态调用。在单态调用的位置,我们其实只需要查找一次 munch 的位置即可(因为类型是相同的,第一次查找之后就可以缓存下来了)。『缓存下来』的实现方式是修改单态调用位置的机器码,把调用函数的地方修改为我们已经查找到的 munch 位置。例如没有做优化之前,animal.munch 生成的机器码可能是这样子的:
function feed(animal, food) {
kOffset = LookUp( animal, 'munch' )
Call( kOffset, food )
}
因为 LookUp 可能比较耗时,通过 PIC 优化之后的机器码就是这样子了,节省了 LookUp 的开销,效率自然提高了:
function feed(animal, food) {
Call( kOffset, food )
}
如果我们可以保证在后续的调用中不会出现其它类型的对象,那么这种处理方式其实工作的很好。然而显示情况下,这种保证是很难兑现的,所以我们考虑到当类型不一致的时候,应该如何去处理。最直接的方式是我们添加一些类型检查的代码,当类型不匹配的时候,再去调用 LoopUp 方法。为了减少内存的占用,我们可以把类型检查的代码放到函数的 JIT 代码中,不需要放到函数调用的地方。例如:
function feed(animal, food) {
if ( GetType( animal ) !== kType ) {
kOffset = LookUp( animal, 'munch' );
}
Call( kOffset, food )
}
但是类型不同的时候(类型切换的时候),我们还是会频繁的调用 LookUp 方法,效率也不会太高,如果解决这个问题呢?我们可以创建一个 feedStub 方法,这个方法的代码可以被动态修改的,例如:
function feed(animal, food) {
feedStub( animal, food )
}
第一次执行之后,feedStub 的实现是:
function feedStub(animal, food) {
var kOffset1 = LookUp( animal, 'munch' );
var kType1 = GetType( animal );
Call( kOffset1, food );
// 更新 feedStub 函数体的代码
GenerateNativeCode( feedStub, kOffset1, kType1 );
}
// GenerateNativeCode 之后 feedStub 的代码
function feedStub(animal, food) {
if ( kType1 === GetType( animal ) ) {
Call( kOffset1, food );
}
else {
......
}
}
第二次执行之后,feedStub 的实现里面有新增了一个 kType2 的判断,这样子我们就可以处理不同类型的对象了。
function feedStub(animal, food) {
if ( kType1 === GetType( animal ) ) {
Call( kOffset1, food );
}
else if ( kType2 === GetType( animal ) ) {
Call( kOffset2, food );
}
else {
......
}
}
但是如果类型特别多,比如几十个,上百个等等,我们把这种情况叫做Megamorphic调用,PICs 技术无法很好的处理这种情况(译者注:为啥呢?),因为在 Megamorphic PIC 代码中确定 munch 函数的位置可能比哈希查找还要慢,所以一般采用 PIC 技术的时候都会需要限制类型的数量。不过时机情况下,Megamorphic调用出现的情况很少,所以影响不是特别大。